
Paralleler Zugriff
Der Admin kann mit diesem Werkzeug auch das Label des Dateisystems ändern, bestimmte Features ein- oder ausschalten (siehe auch
Listing 8
). Leider ist aus der Manpage nicht ersichtlich, welche Änderung online, also im gemounteten Zustand, erlaubt sind und welche nicht. So kann es passieren, dass OCFS2 einzelne Kommandos mit der Meldung
»tunefs.ocfs2: Trylock failed while opening device "/dev/sda1"«
quittiert.
Listing 8
OCFS2-1.4-Features (de)aktivieren
Wie erwähnt erfordern der Cluster-Heartbeat und auch das Fencing keine Vorkonfiguration. Das Initialisieren des Cluster-Stacks stellt Defaultwerte für beides ein. Dennoch hat der Admin die Möglichkeit, die Voreinstellung nach seinen Bedürfnissen anzupassen. Der leichteste Weg führt über
»/etc/init.d/o2cb configure«
. Das Skript fragt die gewünschten Werte ab, zum Beispiel wann der OCFS2-Cluster einen Knoten und wann er die Netzwerk-Verbindung als ausgefallen ansieht. Außerdem legt der Admin fest, wann der Cluster-Stack spätestens ein Re-Connect versucht und wann er ein Keep-Alive-Paket sendet.
Bis auf den Heartbeat-Timeout sind alle Werte in Millisekunden anzugeben. Beim Heartbeat-Timeout, also wenn der Cluster einen Rechner als ausgefallen betrachtet, muss der Admin rechnen. Der Wert gibt die Anzahl der 2-Sekunden-Iterationen plus 1 für den Heartbeat an. Der Standardwert von 31 entspricht somit 60 Sekunden. In größeren Netzwerken kann es nötig sein, alle Werte zu erhöhen, um falsche Alarme zu vermeiden.
Stößt OCFS2 auf einen schwerwiegenden Fehler, setzt es das Dateisystem in den Nur-Lese-Modus oder generiert einen Kernel-Oops oder gar eine Panic. Im Produktivbetrieb kann es durchaus erwünscht sein, diesen Zustand auch ohne gründliche Fehleranalyse schnellstmöglich zu bereinigen, also den Cluster-Knoten zu rebooten.
Dazu muss der Admin das darunterliegende Betriebssystem so modifizieren, dass es im Fall eines Kernel-Oops oder einer Panic sich automatisch neu startet. Die Mittel der Wahl sind bei Linux das
»/proc«
-Dateisystem für temporäre Änderungen beziehungsweise
»sysctl«
, wenn sie Reboots überstehen sollen.
 Abbildung 3: Automatischer Reboot nach 10 Sekunden im Falle von OCFS2-Cluster-Fehlern.
Abbildung 3: Automatischer Reboot nach 10 Sekunden im Falle von OCFS2-Cluster-Fehlern.
Genügend Platz
Wie alle Dateisysteme hat OCFS2 ein paar eingebaute Grenzen, die der Admin beim Design der Datenablage beachten sollte. Die maximale Anzahl der Unterverzeichnisse eines Verzeichnisses ist 32 000. OCFS2 speichert die Daten in so genannten Clustern, die zwischen 4 KByte und 1024 KByte groß sein können. Da die Anzahl der Cluster-Adressen auf 232 beschränkt ist, ergibt sich eine maximale Dateigröße von 4 PByte. Diese Grenze ist aber praktisch irrelevant, denn eine weitere Beschränkung limitiert die maximale OCFS2-Dateisystemgröße auf 16 TByte. Dies folgt aus der Verwendung von JBD-Journaling, das maximal 232 Blöcke à 4 KByte adressieren kann.
Ein laufender OCFS2-Cluster nutzt eine Handvoll Prozesse (
Listing 5
), um seine Arbeit zu erledigen. Für DLM-relevante Aufgaben sind
»dlm_thread«
,
»dlm_reco_thread«
und
»dlm_wq«
zuständig. Die Prozesse
»ocfs2dc«
,
»ocfs2cmt«
,
»ocfs2_wq«
und
»ocfs2rec«
sind für den Zugriff auf das Dateisystem selbst verantwortlich.
»o2net«
und
»o2hb-XXXXXXXXXX«
realisieren Cluster-Kommunikation und Heartbeat. Alle Prozesse werden von den Init-Skripten für das Cluster-Framework und OCFS2 gestartet und gestoppt.
Listing 5
OCFS2-Prozesse
OCFS2 speichert seine Verwaltungsdateien im so genannten Systemverzeichnis des Dateisystems, das für normale Kommandos wie
»ls«
unsichtbar ist. Mit
»debugfs.ocfs2«
kann der Admin aber den Inhalt des Systemverzeichnisses sichtbar machen (
Abbildung 4
).
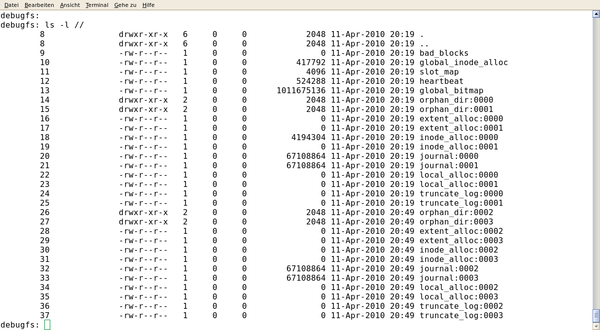 Abbildung 4: OCSFS2 speichert Metadaten als Dateien, die für den Befehl ls unsichtbar sind. Das Kommando debugfs.ocfs2 listet sie auf.
Abbildung 4: OCSFS2 speichert Metadaten als Dateien, die für den Befehl ls unsichtbar sind. Das Kommando debugfs.ocfs2 listet sie auf.
Die Objekte im Systemverzeichnis unterteilen sich in zwei Gruppen: globale und lokale, also knotenspezifische Dateien. Zur ersten Gruppe gehören
»global_inode_alloc«
,
»slot_map«
,
»heartbeat«
und
»global_bitmap«
. Sie sind für jeden Knoten des Clusters zugänglich; Inkonsistenzen verhindert ein Locking-Mechanismus. Auf
»global_inode_alloc«
greifen nur die Programme zum Anlegen und Tunen des Dateisystems zu: So erfordert etwa eine Erhöhung der Slot-Zahl weitere knotenspezifische Systemdateien.
Eine anstehende Installation von OCFS2 wirft die Frage auf, welche Version von OCFS2 denn auf die neuen Rechner soll. Obwohl das Dateisystem an sich, also die Struktur auf dem Datenträger, abwärtskompatibel ist, ist ein Mischbetrieb von OCFS2 1.2 und 1.4 nicht möglich. Schuld daran ist das Netzwerkprotokoll. Die Entwickler haben eine Markierung der aktiven Protokollversion eingeführt. Dies hat den Vorteil, dass künftige OCFS2-Versionen auch im Netzwerkstack abwärtskompatibel sind. Der Preis dafür ist die Unverträglichkeit mit 1.2.
Abgesehen davon hat der Administrator eine gewisse Flexibilität beim Mounten von OCFS2-Datenträgern. Natürlich verstehen OCFS2-1.4-Rechner die Datenstruktur von OCFS2 1.2 und können diese problemlos einbinden. Sogar der umgekehrte Fall funktioniert: Falls das OCFS2-1.4-Volume die neuen Features dieser Version nicht benutzt, dann kann der Admin auch mit einem OCFS2-1.2-Rechner auf die Daten zugreifen.
Ähnliche Artikel




Konfigurationsmanagement

Themen


