
E-Commerce-Applikation in PDQ
Dieser Abschnitt zeigt, wie sich das PDQ-Modell des geschlossenen Systems aus Abbildung 7 einsetzen lässt, um die Durchsatzleistung der dreistufigen E-Commerce-Architektur aus Abbildung 8 vorherzusagen. Wegen der hohen Kosten solcher Installationen sind Lasttests mit einem kleineren Modell der späteren Produktivumgebung die Regel. In unserem Beispiel soll jeweils ein Server jede Stufe abbilden. Ein Testsystem dieser Art eignet sich sehr gut für Leistungsmessungen, wie sie für die Parametrisierung eines PDQ-Modells vonnöten sind. Den Durchsatz misst man in HTTP-Gets pro Sekunde (GPS) und die entsprechende Antwortzeit in Sekunden (s).
 Abbildung 8: Multitier-E-Commerce-Anwendung.
Abbildung 8: Multitier-E-Commerce-Anwendung.
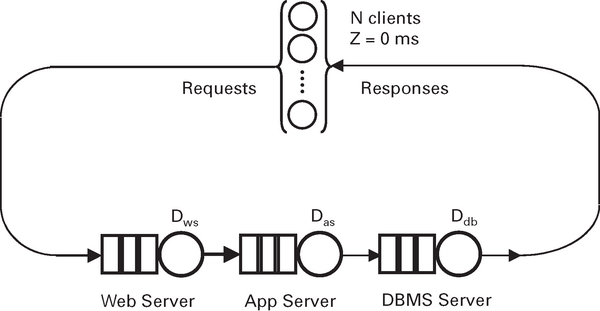 Abbildung 7: Ein geschlossener Warteschlangenkreis mit drei Warteschlangenphasen in Verbindung mit einer speziellen Wartephase (oben), die N Client-seitigen Lastgeneratoren mit einer durchschnittlichen Bedenkzeit von Z entspricht.
Abbildung 7: Ein geschlossener Warteschlangenkreis mit drei Warteschlangenphasen in Verbindung mit einer speziellen Wartephase (oben), die N Client-seitigen Lastgeneratoren mit einer durchschnittlichen Bedenkzeit von Z entspricht.
Aus Platzgründen konzentriert sich dieser Artikel ausschließlich auf die Nachbildung der Durchsatzleistung. Wer sich für Antwortzeitmodelle interessiert, findet dazu Einzelheiten in [5] . Die kritischen Lasttestergebnisse für dieses Beispiel fasst Tabelle 4 zusammen. Leider wurden die Daten nicht mit einer gleichbleibenden Inkrementierung der User-Last erzeugt, was für eine korrekte Leistungsanalyse nicht gerade optimal ist, aber dennoch kein unüberwindliches Problem darstellt. X und R sind Systemmetriken auf der Clientseite. Die Auslastung wurde eigenständig durch Performance-Monitore auf jedem der lokalen Server gemessen. Die gemessene Auslastung (r) und der Durchsatz (X) in Tabelle 4 lassen sich in eine umgestellte Version der Gleichung (3) einsetzen, um die entsprechenden Bedienzeiten für jede Stufe zu ermitteln:
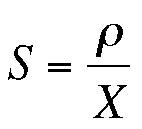 (9)
(9)
Tabelle 3
Die aus Tabelle 4 ermittelten Bedienzeiten
|
N |
Sws |
Sas |
Sdb |
|---|---|---|---|
|
1 |
0.0088 |
0.0021 |
0.0019 |
|
2 |
0.0085 |
0.0033 |
0.0012 |
|
4 |
0.0087 |
0.0045 |
0.0007 |
|
7 |
0.0095 |
0.0034 |
0.0005 |
|
10 |
0.0097 |
0.0022 |
0.0006 |
|
20 |
0.0103 |
0.0010 |
0.0006 |
|
Avg |
0.0093 |
0.0028 |
0.0009 |
Tabelle 4
Gemessene Leistungsdaten in jeder Stufe
|
N |
X |
R |
Sws |
Sas |
Sdb |
|---|---|---|---|---|---|
|
(Clients) |
(GPS) |
(s) |
(%) |
(%) |
(%) |
|
1 |
24 |
0.039 |
21 |
8 |
4 |
|
2 |
48 |
0.039 |
41 |
13 |
5 |
|
4 |
85 |
0.044 |
74 |
20 |
5 |
|
7 |
100 |
0.067 |
95 |
23 |
5 |
|
10 |
99 |
0.099 |
96 |
22 |
6 |
|
20 |
94 |
0.210 |
97 |
22 |
6 |
Naives PDQ-Modell
Der erste Versuch, die Leistungscharakteristik von Abbildung 7 nachzubilden, stellt jeden Anwendungsserver einfach als eigenständigen PDQ-Knoten unter Einsatz der durchschnittlichen Bedienzeiten aus Tabelle 3 dar. In Perl::PDQ wird die Parametrisierung der Warteschlangenknoten so, wie in Listing 3 zu sehen, codiert.
Listing 3
Parametrisierung
Ein Diagramm des Durchsatzes, den dieses erste, sehr einfache Modell vorhersagt, zeigt die Abbildung 9 . Man sieht auf den ersten Blick, dass das naive PDQ-Modell einen Durchsatz prophezeit, der im Vergleich mit den real gemessenen Daten der Testumgebung zu schnell absättigt.
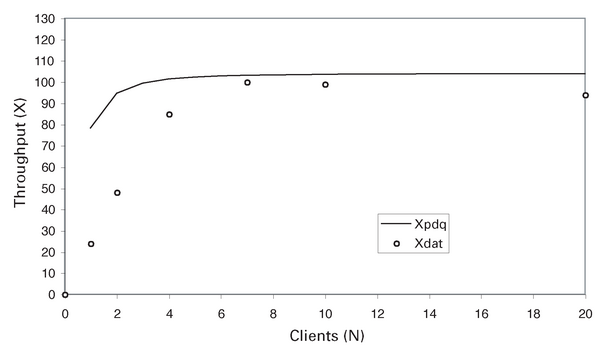 Abbildung 9: Naives PDQ-Durchsatzmodell.
Abbildung 9: Naives PDQ-Durchsatzmodell.
Allerdings teilt uns PDQ ebenfalls mit, dass der bestmögliche Durchsatz für dieses System – auf Basis der gemessenen Bedienzeiten aus Tabelle 3 – etwa 100 GPS beträgt. Diese Leistung wird durch einen Ressourcen-Engpass begrenzt (die Warteschlange mit der längsten durchschnittlichen Bedienzeit), das ist im Beispiel der Webserver. Ihn muss man belasten, sodass der maximale Durchsatz nicht über einen Wert steigen kann, der sich aus der Beziehung (10) ergibt.
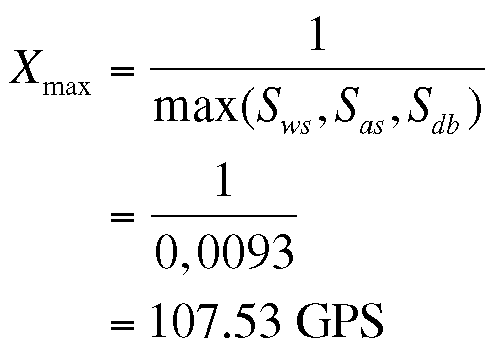 (10)
(10)
Der höchstmögliche Durchsatz wird, wie sich hier zeigt, in unmittelbarer Nähe des errechneten optimalen Belastungspunkts N* erreicht (siehe Tabelle 1 ):
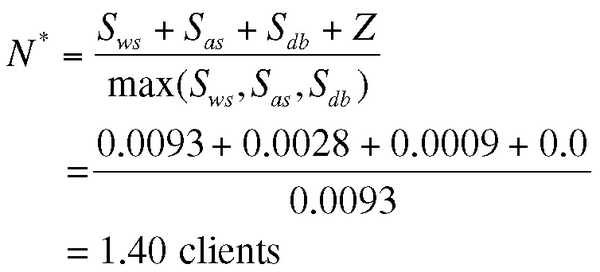 (11)
(11)
Der liegt bei 1.40 Clients. Ändern sich die Bedienzeiten in Zukunft, beispielsweise durch eine neue Release der Anwendung, kann sich der Ressourcen-Engpass verschieben; das PDQ-Modell kann dann die Auswirkung Durchsatz und Antwortzeiten vorhersagen.
Offensichtlich ist es wünschenswert, den gesamten Datenbestand besser nachzubilden als das mit dem naiven PDQ-Modell gelang. Eine einfache Methode, um der schnellen Sättigung des Durchsatzes zu begegnen, wäre, die Bedenkzeit auf einen Wert ungleich null zu setzen ( Abbildung 10 ):
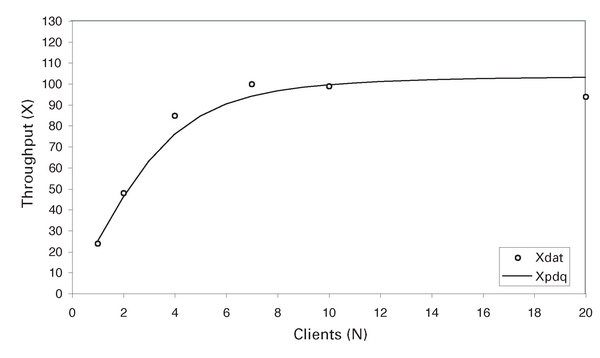 Abbildung 10: Durchsatzmodell mit positiver Bedenkzeit.
Abbildung 10: Durchsatzmodell mit positiver Bedenkzeit.
Z > 0: $think = 28.0 * 1e-3; # freier Parameter ... pdq::Init($model); $pdq::streams = pdq::CreateClosed(U $work, $pdq::TERM, $users, $think);
Auf diese Art werden neue Anforderungen verlangsamt ins System injiziert. Man spielt hier mit der Bedenkzeit, als wäre sie ein freier Parameter. Der positive Wert von Z = 0.028 Sekunden stimmt nicht mit den Einstellungen überein, die beim Lasttest tatsächlich verwendet wurden, aber er kann einen Hinweis darauf geben, in welcher Richtung nach einem verbesserten PDQ-Modell zu suchen ist. Wie Abbildung 10 zeigt, verbessert die positive Bedenkzeit das Durchsatzprofil entscheidend.
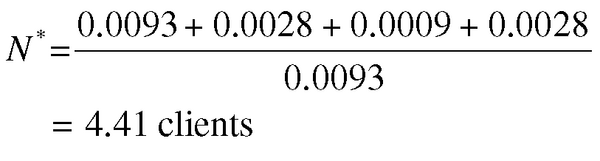 (12)
(12)
Der Trick mit der Bedenkzeit verrät uns, dass weitere Latenzen existieren, die in den Stresstestmessungen keine Berücksichtigung fanden. Die positive Bedenkzeit erzeugt eine Latenz, sodass sich die Round-Trip-Time der Anforderung verlängert. Als Nebenwirkung verringert sich der Durchsatz bei niedriger Last. Aber in der Praxis betrug die Bedenkzeit während der realen Lastmessungen null! Wie löst man dieses Paradoxon?
Ähnliche Artikel





Konfigurationsmanagement

Themen


