
Viele Instanzen & Deduplikation
Eine laufende Instanz eines Alertmanagers kann mit vielen Prometheus-Servern gleichzeitig reden. Wer wie beschrieben Sharding nutzt, weil er enorme Mengen an Servern überwachen muss und eine Prometheus-Server-Instanz mit der anliegenden Last überfordert wäre, benötigt trotzdem nur einen Alertmanager. Der empfängt entsprechende Mitteilungen von Prometheus und dedupliziert sie zunächst. Er verhindert auf diese Weise effektiv, dass er für dasselbe Problem mehrere Alarme gleichzeitig verschickt. Danach gruppiert er die Alarme.
Auf der Gruppenebene legt der Admin im Alertmanager die Alarmierungsregeln fest: Die Alarme einer bestimmten Gruppe können etwa per E-Mail an einen bestimmten Personenkreis versandt werden. Der Alertmanager kann Alarme auch direkt an Slack-Kanäle oder an PagerDuty schicken. Über entsprechende Plug-ins lässt sich aber auch SMS-Alarmierung für verschiedene Anbieter einrichten. Nur eine Einschränkung beim Alertmanager nervt: Der Dienst selbst kann aktuell nicht im Cluster-Modus mit mehreren Instanzen betrieben werden. Wer den Alertmanager selbst also hochverfügbar aufbauen möchte, muss auf einen Failover-Cluster mit Werkzeugen wie Pacemaker oder manuelles Umschwenken setzen. Die Maintainer haben ein entsprechendes Feature zwar auf der Todo-Liste, doch wann es in Form von Code tatsächlich beim Admin im RZ ankommt, ist aktuell unklar.
Eine Schwachstelle von Prometheus hat der Artikel bereits ausgiebig erklärt: Die Prometheus-Server selbst erlauben es aktuell nicht, in die Breite zu skalieren. Sharding steht zwar als Option zur Verfügung, führt allerdings zu administrativen Nachteilen im Alltag. Den Prometheus-Entwicklern ist dieses Problem bekannt: Bereits vor über einem Jahr begannen sie mit der Planung für die Lösung der Schwachstelle. Die nimmt mittlerweile konkrete Konturen in Form von Vulcan an (Bild 4). Aktuell bezeichnen die Entwickler ihren Zögling zwar noch als hochexperimentell, doch es ist bereits absehbar, was Vulcan am Ende leisten soll: Der Dienst holt sich aus verschiedenen Prometheus-Instanzen die dort im Speicher liegenden Daten und legt sie letztlich in Cassandra ab – also einer hochskalierbaren Datenbank.
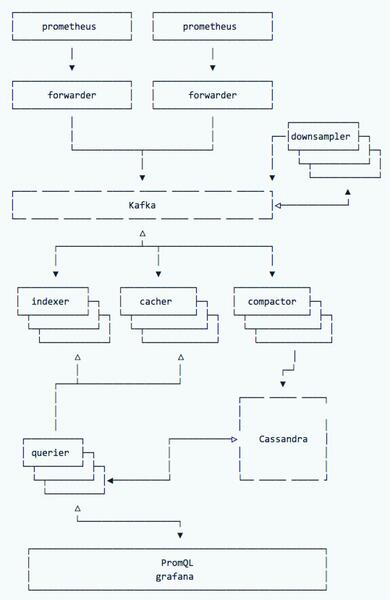 Bild 4: Vulcan legt sich wie eine Klammer um eine Vielzahl von bestehenden Prometheus-Servern und sammelt deren Daten an zentraler Stelle – API für die Abfrage per PromQL inbegriffen.
Bild 4: Vulcan legt sich wie eine Klammer um eine Vielzahl von bestehenden Prometheus-Servern und sammelt deren Daten an zentraler Stelle – API für die Abfrage per PromQL inbegriffen.
Vulcan besteht wie Prometheus wieder aus mehreren Komponenten: Die Forwarder holen die Daten aus den Prometheus-Servern und legen sie in Instanzen der Datenbank Kafka ab. Ein "Downsampler"-Dienst geht die dort hinterlegten Daten durch und kümmert sich etwa um Deduplikation. Die Kafka-Datenbank wiederum dient als Datenquelle für die Index-, Caching- und Compactor-Dienste von Vulcan. Der Vulcan-Querier spricht PromQL und erlaubt damit die Abfrage von Vulcan so, wie sie auch bei Prometheus funktioniert. Vulcan legt sich quasi wie eine große Klammer um alle bestehenden Prometheus-Server herum und bietet die von dort aufbereiteten Daten über eine eigene API wieder an.
Die Lösung ist sehr elegant: Weiterhin vermeiden die Prometheus-Entwickler so die Abhängigkeit von einem überkomplexen, verteilten Speicher. Cassandra wie auch Kafka sind zwar nicht so simpel zu nutzen wie lokaler Speicher, haben in Sachen Komplexität gegenüber OpenTSDB und dem dafür nötigen Hadoop jedoch noch immer die Nase klar vorn. Gleichzeitig bietet Vulcan dem Admin wieder einen zentralen Administrationspunkt, an dem er Zugriff auf sämtliche Daten aller Prometheus-Instanzen erhält. Und weil Vulcan selbst so konstruiert ist, dass jeder Dienst beliebig oft im Cluster vorkommen darf, steht dem Skalieren in die Breite nichts im Wege. Gleichzeitig muss der Admin bei der Einführung von Vulcan sein bestehendes Prometheus-Setup kaum verändern. Auch etablierte Workflows wie Alarming bleiben erhalten.
Fazit
Wer über viele Jahre hinweg mit Nagios & Co. gearbeitet hat, traut dem neuen Prometheus-Braten anfangs vermutlich nicht: Dass Monitoring nur ein Abfallprodukt des ohnehin nötigen Trendings sein soll, kommt einer Revolte in Sachen Monitoring gleich. Und tatsächlich ist Prometheus nicht für jede Art von Setup geeignet. Wer eine Umgebung mit zehn Servern braucht und weiß, dass das Setup nicht wesentlich größer werden wird, fährt mit Nagios, Icinga oder den diversen Alternativen weiterhin bestens.
Wer aber etwa eine Cloud plant, die auf OpenStack basieren soll und möglicherweise von heute auf morgen auch mal um 200 Server zu erweitern sein könnte, kommt um eine umfassende Lösung für Monitoring, Alerting und Trending nicht herum. Hier bietet Prometheus sich als potenter Partner an: Der erste Prometheus-Server lässt sich ohne großes Vorwissen in kurzer Zeit aus dem Boden stampfen und die Lernkurve ist erträglich. Die Dokumentation der Entwickler [4] befindet sich in ausgezeichnetem Zustand und erleichtert so den Einstieg. Die Komplexität von Prometheus ist verglichen mit OpenTSDB und Alternativen wie InfluxDB, Sensu oder Grafana deutlich geringer. Zugleich hat Prometheus alle benötigten Funktionen bereits an Bord.
(of)
Link-Codes
[1] Prometheus-Website: https://prometheus.io/
[2] PromQL: https://prometheus.io/docs/querying/basics/
[3] Prometheus und Grafana: https://prometheus.io/docs/visualization/grafana/
[4] Prometheus-Dokumentation: https://prometheus.io/docs/
Ähnliche Artikel





Netzwerkmonitoring mit Prometheus
Konfigurationsmanagement

Themen


